
Data Modeling in FP vs OOP
At Scalapeño this year, I argued in my keynote that the best and most unique parts of Scala are the ones suited to functional programming—including traits (when used for type classes, modules, and sum types), case classes (when used for product types), higher-kinded types, dot method syntax (which is useful for method chaining and namespacing), and various features of Scala’s type system.
In the Twitter aftermath that followed, I further argued that object-oriented programming—by which I mean inheritance hierarchies (typified by the Scala collections inheritance hierarchy) and subtyping (beyond its use for modeling sum types, modules, and type classes)—isn’t useful. That is, it doesn’t have any real world practical benefits over functional programming.
Some claimed without supporting evidence that Scala’s embrace of object-oriented programming helps working programmers solve real problems. To settle the issue once and for all (at least for some people), I issued the following public challenge:
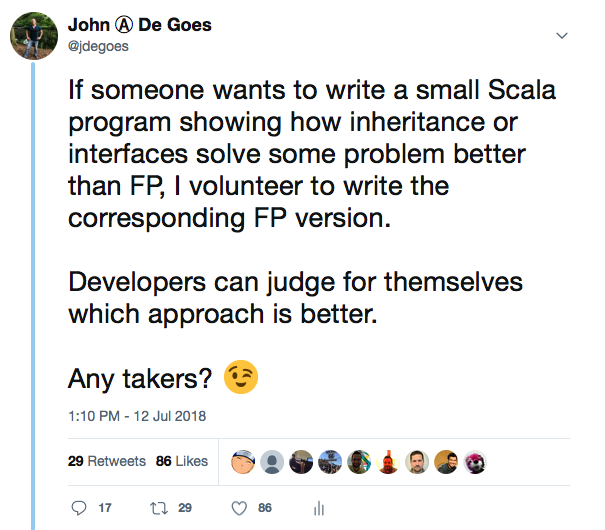
In a world of millions of object-oriented programmers, I received a grand total of 3 responses (!).
In this blog post, I’ll look at one of the responses, and show how you can solve the same problem using standard techniques from functional programming. Then every reader can decide for themselves whether OOP adds anything of value to what I have defined as the good parts of the Scala programming language.
Data Modeling
The first response to my challenge was a problem in data modeling by Christopher Hunt, a veteran of Lightbend:
sealed abstract class Event(val id: Int)
final case class CountersUpdated(
override val id: Int,
counter: Option[Int]) extends Event(id)
final case class DeviceIdUpdated(
override val id: Int,
deviceId: Int) extends Event(id)This example uses inheritance not for type classes, modules, or sum type emulation, but to provide the following benefits:
- The compile-time guarantee that every event has an
idof typeInt, which means the same thing across every event. - The flexibility for each event to have its own custom payload (for example, one has a
counter: Option[Int], and another has adeviceId: Int).
Let’s take a look at how functional programming can provide us with these same benefits, without the use of inheritance.
Naive Solution
In functional programming, we might choose to naively model this problem with a single sum type:
data Event
= CountersUpdated Int (Maybe Int)
| DeviceIdUpdated Int Int// In Scala 2.x:
sealed trait Event
case class CountersUpdated(
id: Int, counter: Option[Int]) extends Event
case class DeviceIdUpdated(
id: Int, deviceId: Int) extends Event
// In Scala 3.x:
enum Event {
case CountersUpdated(id: Int, counter: Option[Int])
case DeviceIdUpdated(id: Int, deviceId: Int)
}While this approach provides us with the ability to vary the payload for each type of event, we don’t have the compile time guarantee that each type of event has an event id.
We could regain this guarantee with classy lenses, but we don’t need anything as fancy as that: we just need to take advantage of the full power of algebraic data types to remove the duplication in our current data model.
Idiomatic Solution
In any case where we have a sum type, whose terms share a common piece of data, we can apply a refactoring: we can extract a new product type with the common data, and push the sum type deeper as another term of that product.
In this case, our event id is the common piece of data, so we can extract a product type that includes both the id and a new sum type that captures differences between different events:
data Event = Event Int Payload
data Payload
= CountersUpdated (Maybe Int)
| DeviceIdUpdated Int// In Scala 2.x:
final case class Event(id: Int, payload: Payload)
sealed trait Payload
case class CountersUpdated(counter: Option[Int]) extends Payload
case class DeviceIdUpdated(deviceId: Int) extends Payload
// In Scala 3.x:
final case class Event(id: Int, payload: Payload)
enum Payload {
case CountersUpdated(counter: Option[Int])
case DeviceIdUpdated(deviceId: Int)
}This simple refactoring now lets us not just vary the payload depending on the type of event, but also lets us have a compile-time guarantee that all events share common data.
Compared with the object-oriented solution, the new data model is the same size (smaller in Scala 3.x!), has all the benefits of the object-oriented solution, and does not conflate abstraction (the capability to extract an id from a type) with the data model.
The new data model is squeaky clean, contains no logic (which is better reserved for type classes, because it’s far more flexible), and precisely models the problem domain!
While developers can argue which approach they prefer, it’s clear the object-oriented solution has no benefits over the functional programming solution.
Summary
In this post, I showed how functional programming compares to object-oriented programming. Rather than use a contrived example that might skew the results in favor of functional programming, I took my example from proponents of OOP.
Stay tuned for other posts in this series, where I look at other challenges problems. And if you have some small, self-contained example, and wonder how to do the same thing in functional programming, please post it in the comments below!