
Bifunctor IO: A Step Away from Dynamically-Typed Error Handling
Bifunctor IO.
The subject is currently one of the hottest topics in the Scala functional programming community, inspiring both fear and awe in equal measure, as well as a proliferation of tickets, pull requests, and blog posts.
The occasion? Scalaz 8 IO has a new bifunctor design that challenges our assumptions about error handling in effect types, and functional programmers all over Scala’s community are trying to decide if and how this design helps us write better software.
Scalaz 8’s greenfield design presents a unique opportunity to re-examine every assumption about functional programming in Scala. The bifunctor design joins other innovations in the effect system (such as fine-grained interruption, resource safety, and fiber concurrency), as well as a growing number of novel features intended to radically improve FP in Scala.
Fibers and interruption were hotly debated when I first introduced them at Scala IO and Scale by the Bay, but now even competitive libraries have moved in the direction of Scalaz 8 IO.
What of bifunctor IO? Is this design going to change the way we manage errors in Scala effect types? Or will it be an interesting footnote in the history of functional programming in Scala?
As a contributor, I’m certainly biased, but I do believe bifunctor IO, which introduces typed errors, is here to stay, and that it’s going to greatly improve our ability to reason about our software. Bifunctor IO helps us describe the properties of our code through the type system, which is what drove many of us to statically-typed FP.
In this post, I’m going to give you an overview of the design and debunk some common myths. You can then decide for yourself if the increased precision is useful.
What is IO?
In many libraries, including Scalaz 7.2 and prior, IO[A] (or Task[A]) is an immutable data type that models an effectful program that runs forever, fails with a Throwable, or computes an A.
Like everything else in purely functional programming, IO is referentially-transparent—and all of its methods, excepting unsafePerformIO or its equivalent, are total, deterministic, and free of side effects.
You can use IO values to build other IO values, in the same way you can use String values to build other String values. It’s very similar to programming with immutable lists, maps, and other data structures common in functional programming, except instead of modeling data structures, the type models IO operations (so-called effects).
Inside your application’s main function, you convert IO into the effects that it models by performing those operations. In Scala, this execution function ships with every effect system, so you can run effects as easily as unsafePerformIO(myProgram).
While “running” an effect is not purely functional, for impure languages like Scala, it’s a necessary evil—at least (and ideally, at most) one place in your application.
I mentioned earlier that IO[A] can fail with a Throwable or produce an A. This bifurcation should remind you of Either[E, A], and indeed, IO data types are effectful versions of Either[E, A], where the E type is either untyped or loosely typed.
Effect types do not throw exceptions, of course. Their notion of failure is exactly like the notion of “failure” with Either[E, A]. Failure is a value and merely short-circuits the remainder of the computation unless the failure is handled. This behaves similar to an exception in all the ways that matter, but it’s just an ordinary value (semantically, anyway, if not always in the implementation).
All effect types ship with equivalents of the following two error management functions:
object IO {
// A function defined on the `IO` companion object:
def fail[A](t: Throwable): IO[A] = ???
}
trait IO[A] {
...
// A method defined on the `IO` data type:
def attempt: IO[Throwable \/ A] = ???
...
}where type \/[A, B] = Either[A, B].
These two functions allow you to produce a value that describes a failed computation (IO.fail), as well as handle a value that describes a failed computation (io.attempt). They satisfy the obvious properties (e.g. IO.fail(t).attempt === IO.point(\/.left(t)), where IO.point lifts a pure A into IO[A]).
General-purpose effect types like IO are how we usually model effects in purely functional programs. Because IO can represent any type of effect and has reasonably high performance, it tends to be the foundation that functional programs are built on. While FP programs may use other effect types, those types usually end up translated into IO.
Lots of programming languages have IO-like types, including of course Haskell (from which the Scala effect types are inspired!), PureScript, TypeScript, Kotlin, and many other languages.
Interestingly, every IO[A] data type in all of these languages has a bifurcated model of computation: either the effect fails with some (dynamically-typed) error, or it succeeds with some value of type A.
What’s Bifunctor IO?
I came up with a bifunctor design for IO in late 2017, and recently upgraded Scalaz 8 IO to support the new design. In this design, IO[E, A] is an immutable data type that models an effectful program that runs forever, fails with an E, or computes an A.
IO[E, A] is a “bifunctor” because you can define an instance of the type class Bifunctor (defined here), which lets you map over not just the value (A => A2), but also over the error (E => E2).
This bifunctor capability of the data type is essential, as it allows you to “lift” programs that produce one class of errors into programs that produce another (typically larger) class of errors.
In bifunctor IO, the two core error management functions are nearly unchanged, but become significantly more general:
object IO {
def fail[E, A](e: E): IO[E, A] = ???
}
trait IO[E, A] {
...
def attempt[E2]: IO[E2, E \/ A] = ???
...
}Instead of being forced to fail an IO with a poorly typed Throwable, you can create IO values that model failure for any error type at all, including strings, numbers, ADTs, or even type-level sets, all of which make sense in different circumstances.
Most functional programs will mix and match many different types of errors at different levels of the application, varying them in response to the local needs of each part of the application.
The attempt function becomes polymorphic in the new error type, allowing you to choose any type of error. This represents a compile-time guarantee that the attempted IO cannot fail, because there is no way it can summon a value of an arbitrary type E2 into existence. You can easily choose the error type of an attempted effect to be Nothing or equivalent (Void in Scalaz, Haskell, PureScript, and others), thus proving that failure is impossible.
The power of this approach can be demonstrated in the following snippet:
def right[A](v: Void \/ A): A =
v.fold(_.absurd[A])(identity)
val io: IO[E, A] = ???
val attempt1: IO[Void, E \/ A] = io.attempt[Void]
val attempt2: IO[Void, Void \/ (E \/ A)] = attempt1.attempt[Void]
val attempt3: IO[Void, E \/ A] = attempt2.map(right)This snippet proves the intuitive fact that repeated attempts cannot fail. The fact that you can express this guarantee at compile-time, using types that communicate rich information to developers, is quite remarkable and powerful.
While error management changes only in minor ways, the resulting ramifications to the error model are profound. Before I explore them, however, we must talk about the different types of errors.
Types of Errors
There are two classes of errors in applications:
- Recoverable Errors. Recoverable errors refer to the errors we expect to happen occasionally. For example, when we perform an https request, we expect that sometimes, it will not succeed because the server is down or there are network issues. Because we expect these errors to happen, we want to build our code in a way that acknowledges the failure scenarios. We want graceful fallbacks at some level of the application (perhaps not locally, but at the edges).
- Non-Recoverable Errors. Non-recoverable errors refer to the errors we do not expect to happen. For example, if a user has configured the JRE with 10k of memory for the stack, then a lot of ordinary (non-recursive) code will stack overflow, producing a
StackOverflowError. This is not a normal error we expect to happen, nor is there a sane way to recover from it.
In Java, the convention is to use Exception for recoverable errors, and Error for non-recoverable errors. Both of these are subclasses of Throwable, which is the only error type supported by the JVM.
In languages like Erlang and C, recoverable errors are modeled with ordinary values, and non-recoverable errors do not have an explicit representation and resolve outside application logic (with a crash in Erlang, and with undefined behavior in C).
The distinction between failure scenarios that we expect to happen and failure scenarios that we do not expect to happen is extremely important:
- Failure scenarios that we expect to happen can be recovered from in application code. In statically-typed functional programming, we have the ability to guarantee at compile-time that expected failures are handled, or at least tracked, so we know the consequences of interacting with such code.
- Failure scenarios that we do not expect to happen cannot be sanely recovered from, and the reason is precisely this: we did not expect these errors, so we do not know where they will occur, what these errors will be, or whether it makes sense to continue, and if so, what remedial actions permit a well-defined recovery.
Attempting to recover from an unexpected error puts your program into an undefined state: it is undefined precisely because you do not know where the error occurred, which means you don’t know the state of the application or its external environment; and you do not know what the error is, which means you don’t know if and how to recover.
Non-recoverable errors are almost always defects, but sometimes they occur for catastrophic reasons outside the direct control of the programmer (such as running out of memory). A C program may overwrite an arbitrary piece of memory (defect), a Java program may try to allocate more memory than reserved for the heap (catastrophic), or an Erlang actor may make a false assumption about data (defect).
The distinction between recoverable and non-recoverable errors fully informs the design of the Scalaz 8 IO error model. In the next section, I’ll introduce this error model and talk about its implications.
A Principled Error Model
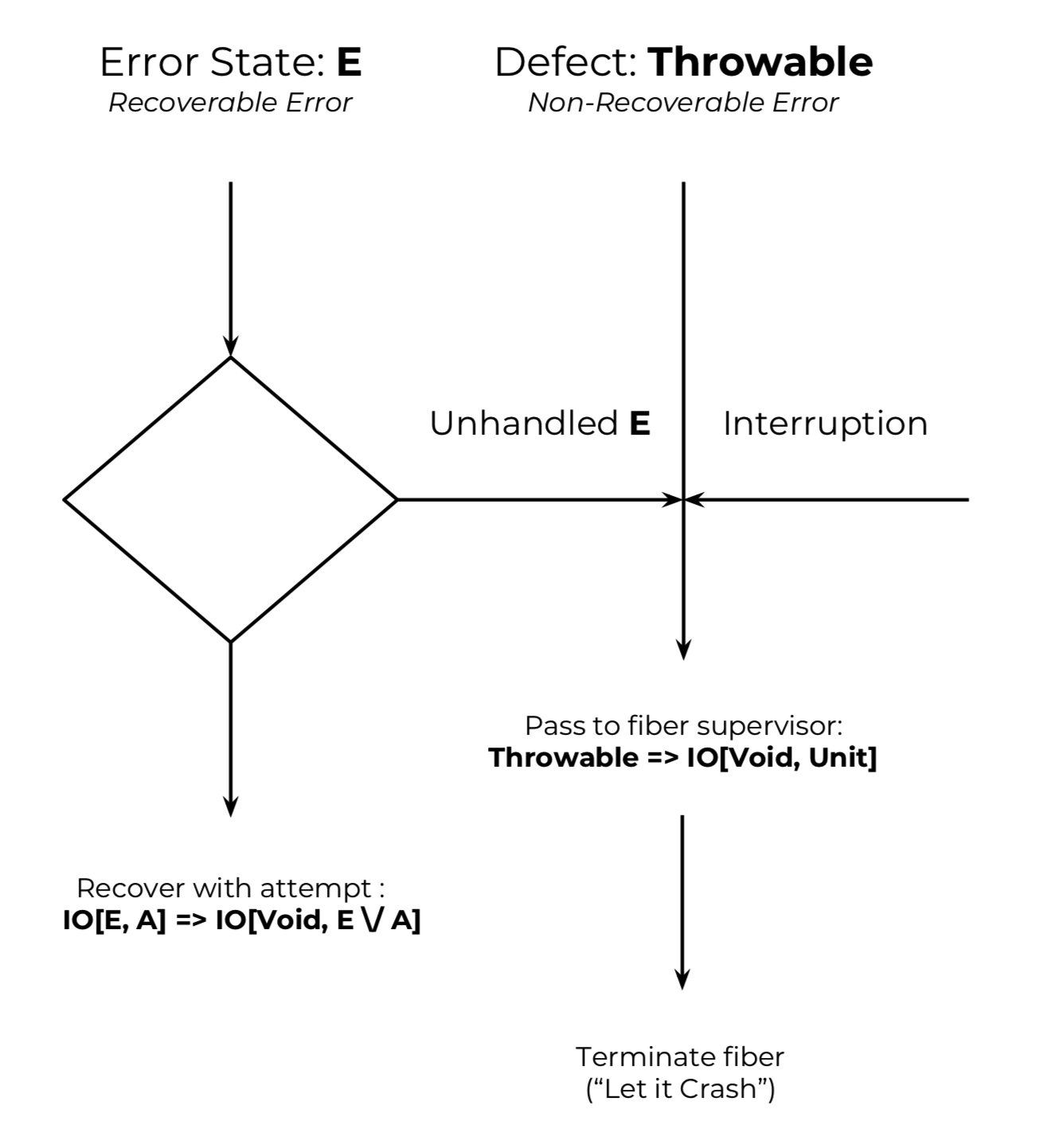
In the Scalaz 8 IO error model, the distinction between recoverable and non-recoverable errors is explicit. This distinction forms the foundation of the error model.
Recoverable errors are statically-typed, and modeled by the E type parameter in IO[E, A].
Effects of type IO[E, A] can fail for any E, and can be recovered from to yield IO[E2, E \/ A], for any type E2, including uninhabited types like Nothing or Scalaz’s Void type. The type system tells you if and how an effect can fail.
Non-recoverable errors are weakly typed, and include the full range of runtime errors on the JVM, which is any type that extends Throwable. Execution of any IO[E, A] may fail due to some non-recoverable error—probably a defect, but possibly a catastrophic error outside the control of the program.
Non-recoverable errors are, as their name suggests, not recoverable, which is the case in languages like C and Erlang. If one of these errors occurs, the fiber running the effect will be terminated.
This error model implies that, aside from non-termination, there are exactly three possible outcomes from running an effect IO[E, A]:
- The effect fails due to an unhandled
Ecreated withIO.fail. - The effect is terminated due to a non-recoverable
Throwable. - The effect computes an
A.
In the sections that follow, I’ll dive into specifics of the error model by covering some of the practical benefits to developers.
Benefit 1: No Dynamically-Typed Errors
The most distinguishing feature of the error model is that it allows us to move away from dynamically-typed errors.
Programming with IO[A] provides no compile-time guarantees about failure. From the type alone, you must assume that all effects may fail for any reason at any time, even if you’ve already handled them or they can only fail in specific ways.
With IO[E, A], you know all possible (recoverable) failure scenarios:
- If you handle some failure scenarios but not others, you can express this in the type by choosing a suitable sum type for
E. - If the effect cannot fail, you can express this with
IO[Void, A]or equivalent. - If the effect may truly fail for any reason, then you can express this with
IO[Throwable, E](or even, heaven forbid,IO[AnyRef, E]).
For one practical application among many, suppose that you want your REST API to return errors in the JSON format. In this case, you can simply express the requirement in the type:
def serve(handler: HTTPRequest => IO[Void, JSON])The type here demands that the handler you pass to the serve function handle all its own errors and encode them into JSON. Now you don’t have to worry about code forgetting to handle some error and then not knowing how to transcribe the error into the required JSON format.
As another example, suppose we have an evaluator in a spreadsheet application for some domain-specific scripting language. In this case, we want to know precisely how evaluation may fail, because failure is expected and we must handle different failures in different ways.
In this case, we can model the evaluator as follows:
sealed trait EvaluationError
case class ParseError(line: Int, expected: List[Symbol]) extends EvaluationError
case class TypeError(expected: Type, actual: Type) extends EvaluationError
case class RuntimeError(function: String) extends EvaluationError
def evaluate(script: String): IO[EvaluationError, Unit] = ???Both statically-typed values and statically-typed errors let us use the compiler to prove properties of our programs. In the case of statically-typed errors, we can prove that effects only fail in specific ways, or that they don’t fail at all.
Further, we can vary our propositions in different parts of our program, because we have the flexibility to vary the type of error.
Feature 2: No Lost Errors
Most programming languages have lossy error models. By lossy, I mean it is possible for exceptions to be swallowed.
In the following snippet, two errors will be swallowed:
try {
try {
try throw new Error("e1")
finally throw new Error("e2")
} finally throw new Error("e3")
} catch {
case e : Error => println(e)
}Most Scala (or Java) developers don’t know which error will be caught and reported in the outermost catch block, but one fact is clear from the structure: at most one exception will be reported. The other two will be lost forever.
Scalaz 8 IO dramatically improves on this broken error model by guaranteeing that no errors are lost, whether they are recoverable errors modeled with E, or non-recoverable errors that result from defects or catastrophic runtime errors.
This guarantee is provided with a hierarchy of supervisors. A supervisor is just a function Throwable => IO[Void, Unit], which will receive all unhandled errors from a fiber.
The root fiber, which runs the application main function, has a default supervisor, which can be overridden. The default supervisor prints the stack trace of the error to the console.
Other supervisors are specified by the application when forking an effect. For example, if you want to run some work in a separate fiber, you call fork0 and specify the supervisor for the fiber:
for {
fiber <- work.fork0(t => logError(t))
...
} yield ()In this example, the supervisor merely logs the error to a file, to ensure if there is a defect in our program, we know that it happened. Other sensible choices include logging to a remote server, restarting a fiber, or returning diagnostic information in an API.
Supervisors are hierarchical. If you don’t specify a supervisor when forking an effect, then it will inherit the supervisor of the fiber that performed the forking.
The supervisor hierarchy provides a modular way of dealing with unhandled errors. Lower levels of an application can decide how to supervise their children, or simply delegate to the parent.
Benefit 3: No Resource Leaks
Scalaz 8 IO has a built-in primitive called bracket, which is a more structured version of try / finally.
The bracket primitive allows you to acquire a resource in one effect, use the resource in another effect, and finally, close the resource in a different effect.
Using this primitive is quite simple:
openFile("data.csv").bracket(closeFile(_)) { handle =>
// Use resource in here...
}Resources acquired with bracket will always be released, even if the body fails due to an unhandled E, a defect in the code, fiber interruption, or a catastrophic external error.
Resource safety lets you build bullet-proof, long-lived applications that are resilient to failures, whether expected or unexpected.
Benefit 4: No Changes Needed
A remarkable property of the Scalaz 8 IO bifunctor design is that it generalizes over both the existing dynamically-typed error effect types and so-called non-exceptional effect types.
Existing effect types may fail at any time, for any reason. To model this type of effect type, we can use the following type alias:
type Task[A] = IO[Throwable, A]With one notable exception, there is no difference between this definition of Task and other dynamically-typed error effects. This is the preferred migration option if you are moving to Scalaz 8 from Scalaz 7.2 IO or Task, Monix Task, or cats-effect IO.
The only difference relates to how defects are handled. Older error models conflate recoverable errors with non-recoverable errors, which “works” because they fix the error type to Throwable. These types encourage users to write code like IO.point(42).map(_ => throw Error("Surprise!")).attempt.
In Scalaz 8 IO, defects in your code cannot be “caught”, similar to Erlang, C, and many other real-world programming languages. Since we use values to represent failure in functional programming (in the case of IO, values constructed with IO.fail), throwing exceptions from pure code is considered a defect, and the fiber running the effect will be terminated.
The cause for the termination will, of course, be passed to the fiber’s supervisor, so it can be logged or otherwise made visible. Or, depending on the context, you might decide to restart a fiber that fails due to a defect, similar to supervision in actor systems.
Aside from this one difference, users who prefer only using Throwable, or who wish to introduce typed errors selectively, can simply use IO[Throwable, A] as their default effect type.
No changes to error handling are necessary, because the bifunctor design completely subsumes older designs.
Benefit 5: No Errors
As discussed previously, IO can also model effects that cannot fail. The following snippet creates a type synonym to do just this:
type Unexceptional[A] = IO[Void, A]Effects of type Unexceptional[A] cannot (recoverably) fail, meaning if they fail, it’s because of a non-recoverable defect in your code or because of a catastrophic error like OutOfMemoryError.
As you can see, IO[E, A] generalizes over both non-exceptional effect types and dynamically-typed effect types. In other words, the bifunctor design of Scalaz 8 IO is strictly more expressive than all other effect types. Other effect types fall out elegantly as special cases.
Developers who complain about the bifunctor design are really complaining because they have gained the ability to be more precise, not because they are required to be more precise. This is rather like complaining about optional type annotations—if you don’t like them, don’t use them!
The alternative to the bifunctor design is to introduce special-case types for non-exceptional or strongly-typed effect types. For example, cats-effect will probably get UIO, which is a non-exceptional effect type, and may at some point get a bifunctor BIO. Such proliferation of effect types (with massive redundancy in the implementations!) is unnecessary with the bifunctor design, because a single generalized type IO[E, A] is capable of modeling everything.
Debunking Myths of Bifunctor IO
The bifunctor design for the Scalaz 8 IO effect type is so new, there’s not much documentation on the subject. Up until recently, the main source of documentation has been the code itself! As a result, the design has been subject to a lot of speculation.
In the next sections, I want to debunk what I perceive to be common myths around the bifunctor design. Arguably, some of these myths are instead strong biases toward dynamically-typed error handling, but most of you who read this blog probably prefer static types, and will share my own bias in this regard.
Myth 1: Composition Destroys Specific Error Types
This myth states that composing two effects IO[E1, A] and IO[E2, B] will result in an error type that erases the distinction between E1 and E2. Stated simply, composing effects leads to a loss of precise error types.
This myth is false because users themselves define how error types compose, and they are not required to use common supertype composition. For example, I can easily combine two effects IO[E1, A] and IO[E2, B] with different errors in a lossless way using a disjunction type, such as E1 \/ E2.
This technique is demonstrated in the following snippet:
val io: IO[E1 \/ E2, (A, B)) =
for {
a <- op1.leftMap(\/.left)
b <- op2.leftMap(\/.right)
} yield (a, b)In general, error types always compose in a completely lossless way using sum types.
In some cases, you may want a built-in sum type like \/ (Either), as shown in the above snippet. In other cases, it is more convenient to define a custom sum type, such as the previously introduced EvaluationError:
sealed trait EvaluationError
case class ParseError(line: Int, expected: List[Symbol]) extends EvaluationError
case class TypeError(expected: Type, actual: Type) extends EvaluationError
case class RuntimeError(function: String) extends EvaluationErrorOthers still may prefer to use type-level sets to represent errors, because this makes it very easy to add and subtract errors, while still providing the ability to handle some or all errors.
The Mitigation library by Jon Pretty, based on Totalitarian, provides a convenient and powerful solution for managing sets of errors. Look for scalaz-mitigation in the near future! (Bug Jon and me about it until we do something!)
Myth 2: You Don’t Recover From Errors Often
This myth states that typed errors are not useful because most code doesn’t recover from most types of errors.
This is only true when recoverable errors are conflated with non-recoverable errors. If an error is not expected, and therefore cannot be recovered from, then it will neither appear in any type signature, nor affect the development experience.
For example, take the following snippet of code:
for {
r1 <- op1
r2 <- op2
r3 <- op3
} yield r1 + r2 + r3If op1, op2, and op3 do not fail in recoverable ways, then they will have type IO[Void, A] (for some type A), which means they compose with effects of any other error type, and we know from looking at the type signature that these operations do not fail.
Only recoverable errors, which we expect to happen, and which we need to deal with in our programs, are reflected in the error type.
Myth 3: The Error Type is an Encapsulation Leak
This myth states that having statically-typed errors leaks implementation details. This is not true at all—in fact, it is poor API design that leaks implementation details.
Let’s take the following API:
def read(id: String): IO[FileNotFoundException, ByteVector]This API states that read can fail with FileNotFoundException. However, we may want to abstract over different ways of reading a resource (in-memory versus over https, for example). If we want to abstract over reading, then FileNotFoundException is a poor way to represent failure. Instead, we should design the API as follows:
def read(id: String): IO[ResourceNotFound, ByteVector]Or possibly even more simply:
def read(id: String): IO[Void, Option[ByteVector]]Whether or not an effect may fail in a recoverable way is part of an API’s public contract, and should be reflected clearly in the types.
API design requires skill, and types alone cannot stop us from making bad design choices. Even without typed errors, we are free to design APIs that leak implementation details.
For example, consider the following API:
def resolve(path: String): Task[File]This API resolves a path to a File resource (java.util.File). However, File only represents local files, and could easily be generalized to URI or something similar. If we must abstract over different resource locations, then File is a poor choice.
No one would suggest that because it is possible to return File, and that File leaks implementation details, we should therefore use AnyRef for all return values so we can let implementations vary.
In the same way, just because it is possible to leak implementation details in the type of an error channel, doesn’t mean we should use dynamically-typed errors.
There is no connection whatsoever between typed errors and the leaking of implementation details. They are completely orthogonal.
Myth 4: It Pushes Complexity to the User
This myth states that using typed errors pushes “complexity” to the user. The myth conflates inherent complexity with incidental complexity.
Inherent complexity is complexity that is inherent to the task of properly modeling a domain. For example, if we wish to precisely model the domain of JSON values, then we must have a sum type that supports boolean, null, numbers, arrays, and objects. Further, our number type must support arbitrary precision.
sealed trait JSON
case object JNull extends JSON
case class JBool(value: Boolean) extends JSON
case class JNum(value: BigDecimal) extends JSON
case class JArr(value: List[JSON]) extends JSON
case class JObj(value: Map[String, JSON]) extends JSONThis is complexity, but it is inherent complexity because it is intrinsic to the problem of precisely modeling JSON values.
Incidental complexity is complexity that arises not because of the problem domain, but because of implementation decisions that could have been otherwise without sacrificing correctness. For example, dependency injection frameworks have much incidental complexity—they are a very complex way of passing arguments to functions.
Precisely modeling data types always comes with some cost due to inherent complexity. Stated differently, making illegal states unrepresentable requires work. If we want to precisely describe if and how our effects may fail, then this, too, will require work, but this complexity is inherent to precise error handling.
A design like Scalaz 8 IO lets you choose how precise you want to be. It has the flexibility to describe infallible effects or effects that fail in only pre-defined ways, but you only need to use this flexibility when you decide the precision adds sufficient value.
Legacy designs remove the choice from you, forcing you into a dynamically-typed error model that offers no ability to make illegal (error) states unrepresentable. They are antithetical to the goals that drive us to statically-typed functional programming.
Myth 5: The Bifunctor IO Doesn’t Reflect the Runtime
This myth states that any effect type should “reflect the runtime”, which is vague enough to warrant sourcing the claim:
“IO needs to reflect and describe the capabilities of the runtime, for good or for bad. All it takes is an ‘innocent’ throw to turn it all into a lie, and you can’t prevent that.”
This is an argument to catch defects, such as exceptions thrown from pure code, so users can attempt recovery. It’s also an argument to fix the failure type to Throwable, because this is what the JVM does.
The argument is incoherent, as can be seen by examining the implications of consistently “reflecting the runtime”.
The JVM does not support parametric polymorphism, which means the A in IO[A] is erased at runtime (equivalent to IO[AnyRef]). Because of this type erasure and the lack of type safety in Scala, this means having a value of type IO[A] is no guarantee the IO value will actually compute an A.
To “reflect the runtime” in the IO data type, it would be necessary to avoid using parametric polymorphism entirely, because this feature is not supported by the JVM, and it’s impossible to enforce that IO[A] actually produces anything of type A. After all, reflecting the runtime would argue, it just takes one innocent, accidental coercion to turn IO[A] into a lie, and you can’t prevent that!
Additionally, the JVM uses null for optionality, not Option or Maybe. Reflecting the runtime would argue for embracing null for optionality, and expecting null everywhere in the interface to IO.
Doing functional programming, even in languages like Haskell, requires a set of assumptions. In Scala, these assumptions include no runtime reflection, no coercion, no exceptions, no side effects, no null, and so forth.
Without these assumptions (often called the Scalazzi subset of Scala, after Scalaz), you would program fearfully, constantly checking the runtime class of every value, testing to make sure no values are null, obsessively try/catching, and fearing that a function like def identity[A](a: A): A may generate a novel A through runtime reflection.
Principled development requires sane assumptions, and pragmatic development requires we know when these assumptions go wrong. The Scalaz 8 error model provides both in a single package, because even though the design assumes you work in Scalazzi, if you don’t, your defects will be captured and reported to supervisors.
Myth 6: Bifunctor IO Doesn’t Let You Use Impure Code
This myth states that because the bifunctor design doesn’t automatically catch defects, you can’t use the effect type with Java code or impure Scala code.
This is not true at all. All code, including exception throwing, impure code, can be trivially imported into IO. In fact, there are three utility functions in Scalaz 8 that do just this:
def syncThrowable[A](eff: => A): IO[Throwable, A]— This function imports code that may throwThrowablevalues, properly translating them intoIO.failvalues.def syncException[A](eff: => A): IO[Exception, A]— This function imports code that may throwExceptionvalues, properly translating them intoIO.failvalues.def syncCatch[E, A](eff: => A)(pf: PartialFunction[Throwable, E]): IO[E, A]— This function imports code that may throw a user-defined range of errors, properly translating them intoIO.failvalues.
These functions let you safely interact with dysfunctional code, which performs side-effects and throws exceptions. You can import this code into pure values, which can interface with your functional code.
Wrapping unsafe code with Try, to safely convert exceptions into values, is something that many Scala developers are already doing. With Scalaz 8, the method you use changes, but not much else.
Myth 7: Bifunctor IO Is Just EitherT
This myth states that bifunctor IO is unnecessary, since we can already achieve the same benefits by stacking the EitherT monad transformer on top of ordinary IO.
There are two flaws in this argument:
- For older effect types
F[_](such as MonixTask, cats-effectIO, and Scalaz 7.2IO/Task),EitherT[IO, E, ?]has two error channels, overlapping instances forMonadError(one having an error type fixed toThrowable), two conflicting ways of failing, and two conflicting ways of recovering from failures. Contrast this toIO[E, A], which has a single error channel. - Scalaz 8 bifunctor IO is functionally equivalent to
EitherT[UIO, E, A]for some infallible effect typeUIO. Although Scalaz 8 IO could be redesigned to be infallible, this would mean as much as a 5x performance penalty for recapturing error handling using anEitherTmonad transformer. As discussed in my last blog post, monad transformers are not practical in Scala.
Scalaz 8 IO brings something genuinely new to the table over EitherT: a clean, typed, single error channel, and high-performance, wrapped in a package that generalizes over all existing effect types.
Final Words
Like other changes in Scalaz 8, including the fiber concurrency model, fine-grained interruption, and resource safety, the bifunctor design of IO requires rethinking assumptions.
This new model doesn’t require you to be more precise, since you’re free to stick with Throwable for all your errors. But it does empower you to describe failure scenarios precisely, and vary if and how effects fail at different levels of your application.
Benefits of the error model are many, and include being able to model infallible effects (non-exceptional IO), use effects the way you’re familiar with (using Throwable everywhere) so you can gradually incorporate typed errors wherever useful, guarantee no resource leaks (even in the event of non-recoverable errors), never lose any errors (unlike other error models), and have strong, compile-time guarantees about if and how your effects can fail.
While there are myths out there about the new bifunctor design, this is expected since there is a scarcity of documentation. Without good documentation, there will always be questions about how a new design works or what the tradeoffs are. Hopefully this blog post succeeds in making the bifunctor design more accessible.
If I’ve convinced you the bifunctor design has value, vote with your feet: support projects like Scalaz 8 IO, encourage contributions like Luka Jacobowitz’s bifunctor IO, and contribute issues and pull requests to your favorite effect type.
Scalaz 8 IO may be the first one to adopt this design, but from the looks of things, it’s not the last. I greatly look forward to seeing others adopt and improve upon the design, to the benefit of the entire Scala functional programming community.